 91云(91yun.co)
91云(91yun.co)按:前些天本站分享了 BBR2 ,但是因为这玩意发包太猛,那怎么样调 BBR 的参数呢?之前 @EvanVane 大佬给我分享过一篇文章,本人实践中也很受用。如果你有一定的技术底气可以看看这篇文章,小白可以略过。另外也请不要伸手党,比如针对 C3 优化的 BBR 对 QN 就不一定适用(网络状况不同),今天调的参数下个月就不一定有用(因为其他人也会调,人家抢带宽后,我怎么样抢更多的带宽?那需要重新调参数。) 这个技术目前看来也不可能出一键包 ,要是想享受,还是好好自学下网络基础吧。
原题: 深夜聊聊 Bufferbloat 以及 TCP BBR 原作者: Bomb250
这篇文章的写作动机来源于知乎上的一个问题,有人问既然 Bufferbloat 是个问题,为什么路由器的缓存还要设计那么大。起初,我也是觉得缓存越大越好,这个就像人们拼命比拼谁的电脑内存大一样,因为在一般人眼里,内存越大就越快!然而对于网络而言,恰好相反,内存越大,越让人不想归家。
酒店舒适,但只是路过,没人会把家装修成酒店的样子,家才是越大越好。
路由器设计成携带大缓存的设备,这是一个错误!路由器不该有那么大的缓存,然而 TCP 大牛当年的一个“ AIMD 错误决定”让路由器的缓存越来越大,最终引发了 Bufferbloat !事情还要从安迪 – 比尔定律说起。
网络上的“安迪 – 比尔定律”
先解释一下安迪 – 比尔定律,即“比尔 . 盖茨拿走了安迪 . 格鲁夫所给的”。狭义的讲就是无论 Intel 的芯片快到多么牛逼的地步,微软的下一个 Windows 版本总是能把芯片的性能榨干,然而广义的讲,安迪 – 比尔定律连同摩尔定律一起事实上构成了信息产业的一台泵,典型的一个正反馈系统,这是决定互联网产业大爆发的本质原因,这个系统如下:
摩尔定律 -> 硬件性能提升 -> 软件填补硬件提升的空间
我们可以理解为,摩尔定律和安迪 – 比尔定律驱动了信息革命的车轮不断滚动从而碾压一切!
可以把路由器的越来越大的 Buffer 以及 TCP 贪婪地占据这些路由器 Buffer 两者看作是另一个“安迪 – 比尔定律”。因为 BBR 之前的 TCP 拥塞算法都是盲目且贪婪的,路由器加大的 Buffer 总是能被 TCP 的 AI( 加性增窗 ) 过程快速榨干,反过来大缓存延迟了 TCP 的丢包,同时增加了丢包的成本,这要求路由器提供更多的缓存。
具体来讲就是,如果路由器 Buffer 过小,基于丢包的拥塞算法固有的全局同步现象将会使得带宽的利用率极低,所以必须增加 Buffer 来弥补。这就是一个正反馈循环,肇事者可以说是基于丢包的 TCP 算法,它驱动了路由器 Buffer 越来越大,当 Buffer 越来越大, TCP 又会瞬间用完,永远喂不饱,直到永远。
好在有摩尔定律和 TCP 的 MD( 乘性减窗 ) 过程二者从中协调,如果同时失去了二者, TCP 早晚会全局崩溃!
我们假设硬件已经逼近了热密度的极限,摩尔定律失效了,此时不会再增加 Buffer 的大小了,会发生什么呢?
只要有 TCP 的 MD 过程在,互联网就不会崩溃,所以说, TCP 的 AI 过程保障了其效率,而 MD 过程则保证了收敛。
Google 的新拥塞控制框架来了以后, MD 过程便不被保证了,任何人都可以写一个永不降窗的算法,如果把主动的 MD 过程看作道德的话,那么路由器的 AQM 就是法律了。这就是 TCP/IP 的几乎全部内容了,我们可以看到,它极其复杂。
值得注意的是, TCP/IP 的安迪 – 比尔定律展现的这种复杂性,其促进因素不是摩尔定律,而是“人们对带宽的高利用率的追求”,因此便有了以下的关系:
提高带宽利用率 -> 路由器加大 Buffer->TCP 的 AIMD 填补加大的 Buffer
其实,这完全是错觉, TCP/IP 的框架不该这么复杂的。或许, AIMD 根本就不需要,事实上,是路由器不断加大的 Buffer 和 AIMD 一起纵容了坏事的频繁发生。这一点正如人们不断买新电脑,不断买新手机,然而过不了多久,你依然会发现不管再新的机器都卡的要死一样的道理,只不过,人们买的电脑也好,手机也好,它们的更新换代是摩尔定律驱动的,机器完全是个人所有的,你随时可以跟着摩尔定律的节奏更新换代,然而对于网络设备却不是这样。
网络设备,比如路由器,交换机之类,它们只是整个 TCP/IP 系统的一个环节而已,机房里面的设备是不可能频繁更新换代的,摩尔定律几乎被它们所无视。虽然摩尔定律依旧影响着设备的实际制造和升级,但由于这种周期相对较长,也就是可以忽略的了。但这里面有一个不变的定论,那就是 TCP 几乎全部都是以 AIMD 原则来运作的, UDP 则是无限贪婪的。 TCP 的 AI 会造成主动丢包,这也是基于丢包的拥塞控制算法的核心,而 MD 会造成全局同步,这两点无疑造成了带宽利用率的低下,这是 TCP 的硬伤,不得不靠不断加大的路由器 Buffer 来弥补,至少是延迟了悲剧的发生,在延迟悲剧的这段时间内,路由器当然希望端系统可以意识到事情正在悄悄起变化并采取一些措施。
……
AIMD ,正如以太网的 CSMA/CD 一样,并不完美,但是可用。现在的人们在千兆以太网出现之前,曾经推导出一个结论,那就是依靠 CSMA/CD 是不可能达到千兆 bps 的,然而如今已经是万兆甚至 4 万兆了 … 如果说以太网的载波监听,冲突检测是不必要且可被替换的,那么 TCP 的 AIMD 也是不必要且可被替换的,二者简直太像了!
Bufferbloat 问题
我不想说 TCP 的 AI/MD( 加性增和乘性减 ) 是错误的,我也不敢给出如此决绝的否定,然而,至少我想表达的是,在“安迪 – 比尔定律”的作用下, AI/MD 是有问题的!什么问题呢? Bufferbloat 问题!
再次重申,路由器携带很大的 Buffer ,是错误的!路由器 Buffer 在够用前提下越小越好,没有 Buffer ,自然就不会 bloat ,本来无一物,何处惹尘埃?!但是不能没有 Buffer…Buffer 到底是用来干什么的?到底多少合适?
Buffer 其实就比较类似我们吃的食物,曾经,在物资贫乏的年代,大家都在追求要多吃,现在营养过剩了,则反过来了,要少吃,实际上,人体根本不需要太多的食物,够用即可,人体大部分的精力要用来做更有意义的事情。同样基于存储 / 转发 TCP/IP 网络上的路由器其根本任务不是做存储,而是做转发,存储只是在理论上不得已的一个手段。我来解释下是为什么。
路由器的入口和出口分别接收到达的数据包和转发数据包,一台路由器上往往有多个接口同时全双工地进行接收 / 转发,数据包的到达频率是统计意义上的,符合泊松分布,然而数据包的发送则是固有的接口速率,这是分组交换网的核心根基!路由器扮演什么角色?它是一个典型的多服务台排队系统!所以路由器必须携带一个 Buffer 用来平滑泊松分布的包到达和固定速率的包发送之间的关系。
那么,设计多大的 Buffer 合适呢?按照排队理论的现成公式计算,够用即可!
我们考虑极端一点的情况,如果我们把存储队列的 Buffer 设计成无穷大,从而转发延迟也将是无穷大 ( 因为排队延迟会趋向无穷大 ) ,会发生什么?无疑,这台路由器将会变成一个超级存储器,它将会拥有全世界所有的信息!
爆炸!转发设备变成了存储设备!这就是 Bufferbloat 。注意, Bufferbloat 的恶劣影响并不是会造成丢包,而是会无端增加无辜连接的延迟。这里有个认识上的误区,这种认识在中国人的思维中特别明显。很多人会觉得 Bufferbloat 会造成“丢包反馈延迟增加”,其实丢不丢包是你自己的事,如果你通过 RTT 梯度检测到了 Bufferbloat ,你依旧继续猛发,结果被 AQM 给丢了,那完全是你自己全责,事实上,这个时候大家都应该全局 MD 才对。
真正的危害在于,由于 Bufferbloat 造成了整个大 Buffer 被填充,所有的数据包都将等待一个固有的排队延迟,这会严重影响任意经过的实时类应用!千万别扯什么 QoS ,区分服务,综合服务,流量工程什么的,这些要真有用, 120 救护车就不会被堵在路上了,请注意,事在人为,事在人不为。
我最喜欢的其实不是 TCP/IP 网络什么的,而是城市规划,道路规划以及机械设计 (2002 年我的专业就是机械工程 ) ,我只是在 2004 年的时候初识了路由器,交换机之类的东西,发现自己竟然可以不用挖地铲土浇筑建桥就可以完成一条自己想象中的道路,并且还有那么多的现实场景,这不禁可以让人随时进入禅境 … 实际上,关于城市规划,道路规划以及机械设计也有很多电脑上的模拟器,但问题是它们毕竟只是模拟,是不真实的,而路由器,交换机是真实的,它们就摆在那,登录设备打开 Monitor ,我看到的是真实的东西,这与模拟器有大不同。
在后来的学习中,我发现路由器交换机之上有个 TCP/IP ,折腾起来一点也不比挖地铲土浇筑建桥来的轻松,但至少除了搬机器,上架,插线之外,没有什么体力活了,也还好。
路由器 Buffer 是什么?以高架路为例,它相当于上匝道前面的位置:
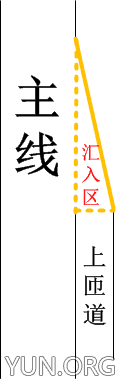
图中的汇入区就相当于路由器的 Buffer ,可以看出,如果汇入区过大的话,单位时间内就会有更多的车辆汇入主线,当这个量超过主线流量的时候,就会造成汇入区拥堵,同时大大降低主线的通行能力。这意味着,很多无辜的车辆被堵在了汇入区,主线上的车辆也会由于汇入去有大量车辆汇入而显示拥堵迹象,我给出给具体的例子吧,那就是上海南北高架广中路由南向北上匝道,那个汇入区太长了,足足 200 米 + ,结果造成那个位置几乎持续拥堵,不光广中路上匝道新上南北高架的车辆走不动,就连主路上的车辆也被拥堵,这是什么造成的?这是错觉造成的!广中路上匝道下面准备上高架的司机一看匝道是空的,唰唰全上去了,结果堵在汇入区了 …
如果广中路上匝道的汇入区修的短一些,那么拥堵只会体现在上匝道或者广中路路口,这种拥堵反馈到准备上高架的司机那里,结果就是,要么等,要么绕,至少会阻止他们上主线汇入区去添堵,伤害无辜的流量。
好了,该回到 TCP 了。路由器 Buffer 减小有什么好处呢?好处在于,即使有连接拼命去 AI 添堵,那么丢包会很快到来,并且很快反馈给发送方,于是发送方会执行 MD 以表示忏悔,整个过程中,实时流量不会受到丝毫影响。
劣币驱良币
BBR 是什么我就不解释了,我写了很多文章。这些文章中没有提到的是, BBR 属于那种即便上匝道汇入区修的再长也不上去添堵的德国好司机。那么结果是什么?你以为这种行为会感动全中国吗?
错了,这正是中国人所期许的,你谦让,我就流氓。你不去堵,我去堵。结果就是, BBR 即便不去主动添堵,也会被其它人堵在路上, BBR 只能说,这拥堵不是自己造成的,仅此而已。吃亏做好事又不被认可反被讹,这是我们这里常有的事, BBR 到了中国应该入乡随俗,你堵,我也堵!
BBR 开始为网络添堵
永远不要欺负老实人, BBR 开始做损人不利己的事了。在中国,所有的 TCP 拥塞控制算法都无法被公正评估,请注意,这个修改的意义在于, BBR 对于自身的性能没有任何提升,只是为了损人而已。我跑得慢,我踹你一脚把你整瘸了,你会更慢,这样我就第一了,竞速,竞速而已!
那么,这件坏事如何来做呢?
我的第一个版本不公开,事实证明它更有效,起码上了我的版本,别的就没的跑了,但问题是上两个我的版本,他俩双胞胎也会打架打得头破血流 … 本着和谐共存的原则,我从不教人学坏,所以我会删除并忘掉代码,再不提起。我这里给出稍微温和点的版本,兄弟俩打架的情况依然存在,但不严重,问题是,如何区别对方是否是自家人 … 难!
BBR 计算总的最大发送量的时候,不是按照 max-Bandwidth 和 min-RTT 的乘积计算的吗?我这里维护了一个最小 RTT 窗口内的 max-RTT ,只要在一个最小 RTT 窗口内的实际 RTT 不大于上一次的 max-RTT ,我就让 BBR 使用这个实际的 RTT 而不是什么最小的 RTT 。这里的原则在于, BBR 会尝试在排队不丢包的情况下也去主动排队,入乡随俗。
代码非常简单,先为 BBR 增加一个字段,即 max_rtt_us ,与 min_rtt_us 相对,然后修改 update RTT 和 calc CWND 的逻辑:
1. 修改 bbr_update_min_rtt
/* Track min RTT seen in the min_rtt_win_sec filter window: */
filter_expired = after(tcp_time_stamp,
bbr->min_rtt_stamp + bbr_min_rtt_win_sec * HZ);
if (rs->rtt_us >= 0 &&
(rs->rtt_us <= bbr->min_rtt_us || filter_expired)) {
bbr->min_rtt_us = rs->rtt_us;
bbr->min_rtt_stamp = tcp_time_stamp;
bbr->rtt_us = rs->rtt_us;
if (filter_expired)
bbr->max_rtt_us = rs->rtt_us;
}
bbr->rtt_us = bbr->min_rtt_us;
if (!filter_expired && rs->rtt_us >= 0 && rs->rtt_us < bbr->max_rtt_us) {
bbr->rtt_us = rs->rtt_us;
}
2. 修改 bbr_target_cwnd
if (inet_csk(sk)->icsk_ca_state != TCP_CA_Open)
w = (u64)bw * bbr->min_rtt_us;
else
w = (u64)bw * bbr->rtt_us;
最大 RTT 和最小 RTT 之差就是排队延迟,充分利用这个排队延迟去添堵是一件简单的好事,但是如何去对抗 AQM 则是一件非常复杂的事,因为你并不知道 AQM 的行为。以上的讨论均建立在尾部丢包的基础之上,然而现实情况则要面临复杂的 AQM ,在文章《 Linux Kernel 4.9 中 TCP BBR 算法的科普解释 》的“君莫舞,君不见玉环飞燕皆尘土”以及“ BBR 的优势之 – 与 AQM 的关系”两节中,我有阐述 BBR 如何乐观地等待 CUBIC 之流被惩罚以及如何愉快地上位,然而在“广中路上匝道”情形中, CUBIC 并不会被惩罚, BBR 自然也就不会上位,那怎么办,只能添堵,至于 AQM 怎么处理,一视同仁吧。换句话说, BBR 在 CUBIC 以及任意所谓“ TCP 加速者”面前,不必客气,他们抽烟,你就放火。
快递或者网络可靠吗
现在人们没了互联网就不能生活,这也是一种错觉。
其实互联网本身就是一种错觉,它是一种不得已而为之的错觉!
去年 1 月我去深圳万象城 ( 之所以说万象城而不是人人乐,我是想说我买的东西有多么高大上,以至于我多么迫不及待地想拥有 ) 买东西,无货,咋办?店主说次日可取,他们从广州拿货。现在问题来了,去一趟广州难吗?为什么我自己不直接去广州买,还要深圳万象城去广州拿货后再卖给我?因为我没时间!如果我有大把的时间又那么喜欢那件物品,我肯定自己去广州了,顺带旅游,然而我缺的正是时间。
快递业务填补了人们的时间间隙。但是快递业务真的可靠吗?
如果我自己去广州拿货,假设高铁不脱轨,汽车不翻车,自己不被人捅的情况下,一路上我愉快地去,拿到货后愉快地归来,一路上我亲自护送货品,我放心,我踏实。如果交由快递,我不知道快递车会不会翻车,会不会被人抢,里面会不会是假货 … 一切我都不确定,在送到我手里前,我只能祷告 ~ !但好处在于,这段送货的时间,在我信任快递公司的前提下,我可以做别的工作,如果我不信任快递公司,我只能心急如焚。好在,现在的快递公司,特别是顺丰还算靠谱,你不需要心急如焚。
但是网络,其可靠性完全是另一回事,幸亏人们用了 TCP ,不然就别玩了。字节的复制往往比丝帛的织造更加廉价,所以 TCP 有一个存储重发的机制,发送信息前先存储信息,一段时间没有收到回应,就重发被存储的信息,收到回应则将信息删除,如果发了一批丝绸到远方,一段时间没有反馈,然后再去织一批新的,那代价可就大了去了 …
我不亲自去广州而去委托快递公司,正是因为我没有时间,那么如果快递公司的快递过程“弥补”了我本应该节省的时间 ( 比如快递员懒惰 ) ,我还不如自己去拿货呢。
网络也一样,如果网络的延迟太高,那还不如用 U 盘拷贝信息,用汽车运输 U 盘,然后交付呢 … 网络和快递一样,就是图快,用专业的运输代替你自己的自取。然而,如果网络中有 Bufferbloat ,那么还不如去自取,甚至去用 U 盘拷贝。
Bufferbloat 让网络丧失了快速传输通道的名声。
新的 Bloat 版本的 BBR 算法
周日早晨,我登录到了温州老板提供的位于国外的 VPS 机器上,演绎了一个新版的 BBR 。也是添堵版的,在我的 WIFI 环境下碾压了标准的 BBR ,这就好像魔人布欧的分身一样,一个是好人的时候,另一个必须是恶棍。
非常简单:
1. 为 bbr 增加一个 minmax 类型的 max_rtt 字段
2. 修改 bbr_update_min_rtt 函数
filter_expired = after(tcp_time_stamp,
bbr->min_rtt_stamp + bbr_min_rtt_win_sec * HZ);
if (rs->rtt_us >= 0 &&
(rs->rtt_us <= bbr->min_rtt_us || filter_expired)) {
bbr->min_rtt_us = rs->rtt_us;
bbr->min_rtt_stamp = tcp_time_stamp;
bbr->rtt_us = rs->rtt_us;
}
bbr->rtt_us = rs->rtt_us;
rtt_prior = minmax_get(&bbr->max_rtt);
// 迄今为止最大的 RTT 与当前 RTT 取其小!是不是拿最大 RTT 和最小 RTT 求个 " 平均 " 什么的更合理呢?
// 反正我是占点 Buffer 空间
bbr->rtt_us = min(bbr->rtt_us, rtt_prior);
minmax_running_max(&bbr->max_rtt, bbr_bw_rtts, bbr->rtt_cnt, rs->rtt_us);
我祝愿所有的 TCP 连接早日崩溃,我祝愿互联网越来越拥堵,最终不可用。
为什么 BBR 是合理的
AIMD 是基于丢包的拥塞控制算法的根基,这必然会 Buffer bloat ,解决之道就是不采用基于丢包的算法,而采用基于时延的算法,但是 ….
但是只要有一个基于丢包的算法还跑在互联网上,那么所有基于时延的算法都会集体退让 … 这是基于时延算法弊端,既然它基于时延而不是丢包,那么它就是注定要吃亏的。正确的做法是什么?
BBR 无视丢包 ( 也并非绝对, BBR 在处理非 Open 状态时还是有措施的 ) ,无视时延 ( 也非绝对, BBR 只是无视了 RTT 的瞬时变化值 ) ,采用了实时采集并保留时间窗口的策略,这初看起来是吃亏的算法,与基于时延的算法无异,但是 BBR 拥有 Probe More 和 Drain Less 过程,这非常合理。
合理的并不意味着是可用的。我依然祝愿所有的 TCP 连接早日崩溃,我祝愿互联网越来越拥堵,最终变得不可用。我有一个梦想,每个人抡起铁锤去炼钢,少说多做,最好不说。

还是怎么说。。
tcp加速有一个人开其他人都跟着开
最后boom
然后大佬开发出新技术 有人享受了新技术 其他人跟进
然后请回到上一行的上一行
6666
没那么恐怖,一句话:
天塌下来了谷歌和Linux 基金会顶着。
说到底都是mjj和小学生在坏事
蛋糕是有限的
天朝出口已拥堵不堪
如果大家都不用tcp优化这种,那大家不就都回到原点?实际上和用了一样。
恩,很有道理~~~~